Approche fine tuning 🔧
Collecte des données 📊
Pour recueillir les données destinées à l’entraînement de nos modèles, nous avons exploité la plateforme Kaggle Kaggle [2024] qui constitue une base de données en ligne dédiée aux projets de Data Science. Cette plateforme nous a donné accès à cinquante ensembles de données distincts portant sur les avis de clients concernant cinquante marques de véhicules différentes. Tous ces ensembles de données présentent une structure uniforme avec les mêmes noms de colonnes, comprenant notamment : - Review_Date : La date à laquelle l’auteur a publié son avis. - Author_Name : Le nom de l’auteur ayant rédigé l’avis sur le véhicule. - Vehicle_Title : Le titre ou le nom du véhicule objet de l’avis. - Review_Title : Le titre donné par l’auteur à son avis, offrant un aperçu du contenu. - Review : Le texte détaillé de l’avis rédigé par l’auteur sur le véhicule. - Rating : La notation attribuée par l’auteur pour évaluer le véhicule, généralement sur une échelle (par exemple, de 1 à 5 étoiles). Ces colonnes renferment des informations cruciales sur les avis relatifs aux véhicules, telles que la date de publication, l’auteur, le véhicule concerné, le titre de l’avis, le contenu de celui-ci, ainsi que la note attribuée
Traitement des données
Étiquetage
Cette phase du projet revêt une importance cruciale, car elle implique la création de notre colonne cible (“Target”) qui stockera les listes de pièces de véhicules. Pour ce faire, nous avons effectué du web scraping sur deux sites web : wikipedia.com [wik] et listexplained.com [lis]. Ces sites nous ont fourni un accès à une liste non exhaustive de pièces de véhicules, totalisant environ sept cents références. Nous sommes conscients que notre liste ne couvre pas toutes les pièces de véhicules et ne prend pas en compte toutes les appellations possibles pour une même pièce. Cependant, pour le moment, nous nous en tiendrons à cela et nous améliorerons notre liste au fil de notre progression. Pour conclure cette phase d’étiquetage, nous avons parcouru l’ensemble de notre ensemble de données, créant ainsi deux nouvelles colonnes : - “List_part” : qui contient une liste des pièces de véhicules trouvées dans chaque avis. - “Count_part” : qui indique le nombre de pièces présentes dans chaque avis. À ce stade, nous pouvons affirmer que notre ensemble de données est en bonne voie et que nous sommes prêts à passer à l’étape du fine-tuning.
Préparation du dataset pour le fine-tuning
Une fois que nous avons déterminé que le fine-tuning est la solution appropriée, indiquant que notre prompt a été optimisé au mieux de ses capacités et que des problèmes persistants avec le modèle ont été identifiés, il est impératif de préparer les données pour l’entraînement du modèle. Dans cette étape cruciale, nous devons constituer un ensemble varié de conversations de démonstration, similaires aux conversations auxquelles nous demanderons au modèle de répondre lors de l’inférence en production. Chaque exemple dans notre jeu de données doit être une conversation structurée selon le même format que notre API de complétion de chat, comprenant une liste de messages où chaque message a un rôle, un contenu et éventuellement un nom. Il est essentiel d’inclure dans ces exemples d’entraînement des situations où le modèle sollicité ne se comporte pas comme souhaité. Les messages fournis en tant qu’assistant dans les données doivent représenter les réponses idéales que nous souhaitons que le modèle fournisse. Cette approche garantit que le modèle est formé sur des exemples diversifiés et spécifiques, incluant des cas où des améliorations sont nécessaires. Cela permet de guider le modèle vers les réponses idéales que nous attendons dans des situations variées lors de l’utilisation du modèle en production. La dernière étape consiste à formater notre dataset, pour cela nous avons ajouté une séquence de fin à tous les prompts : il termine par la chaine de caractère “-> ” qui indique au modèle qu’il peut commencer à faire la complétion c’est-à-dire générer la liste des pièces ; et une séquence de fin, toutes les complétions se termine par le mot ” END” pour indiquer au modèle qu’il doit s’arrêter, on fait cela pour éviter que le modèle ne continue de générer des mots non souhaités. Et maintenant nous convertissons notre dataset en fichier Jsonl qui sera le format utilisé pour le fine-tuning
Entrainement des Modèles
Après avoir minutieusement préparé et formaté nos données, nous entamons la phase d’entraînement, cruciale pour la création du modèle. Pour ce faire, nous utilisons l’outil en ligne de commande (CLI) d’OpenAI, exécutant ainsi une série de commandes. Nos données sont ensuite téléchargées, accompagnées des hyperparamètres que nous avons définis, et le processus d’entraînement est enclenché. Dans notre approche, nous avons choisi un processus d’entraînement itératif qui permet un ajustement continu du modèle, affinant ses performances de manière constante. Cette méthodologie de fine-tuning itératif implique plusieurs cycles d’amélioration du modèle, contrastant avec une seule itération de fine-tuning. Nous adaptons progressivement notre modèle, perfectionnant ses performances au fil des itérations. L’objectif principal de ce projet est de former un modèle polyvalent capable d’accomplir diverses tâches de détection, notamment la reconnaissance des noms de pièces, l’identification des problèmes liés aux pièces ou les défauts, ainsi que la compréhension du contexte. Initialement, nos efforts se concentrent exclusivement sur la détection des noms de pièces, puis nous intégrerons progressivement les autres objectifs au fil du temps.

Évaluation des modèles
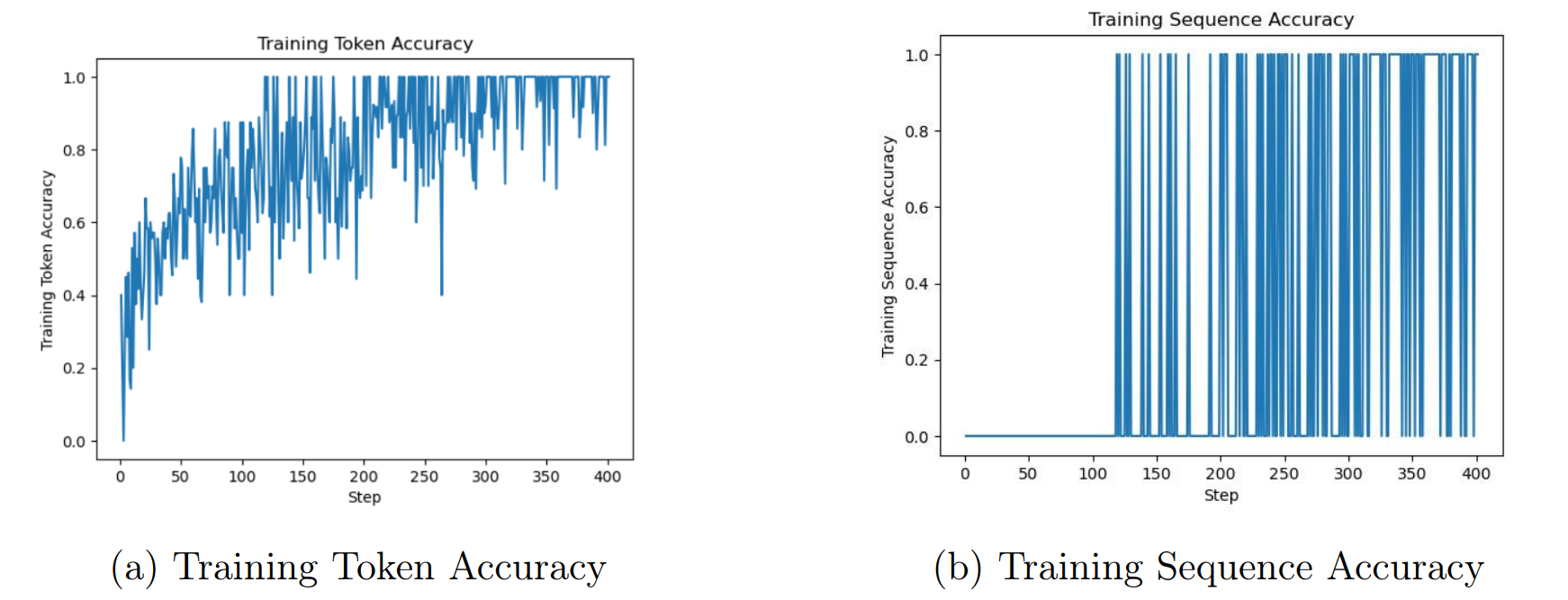
Notre premier modèle, partfinder_t_001, a été entraîné sur 1000 lignes de notre ensemble de données, représentant ainsi 5,56% du total. À la suite de l’entraînement, les performances du modèle sont accessibles dans un fichier results.csv. Ce fichier contient une ligne pour chaque étape d’entraînement, où une étape fait référence à une passe avant et arrière sur un lot de données. - elapsed_tokens : le nombre de jetons que le modèle a traités jusqu’à présent (y compris les répétitions) - elapsed_examples : le nombre d’exemples que le modèle a traités jusqu’à présent (y compris les répétitions), un exemple correspondant à un élément du lot (batch). Par exemple, avec batch_size = 4, chaque étape augmentera elapsed_examples de 4. - training_loss : la perte (loss) sur le lot d’entraînement - training_sequence_accuracy : le pourcentage de complétions dans le lot d’entraînement pour lesquelles les jetons prédits par le modèle correspondent exactement aux jetons de complétion réels. - training_token_accuracy : le pourcentage de jetons dans le lot d’entraînement qui ont été prédits correctement par le modèle. L’évolution des performances de notre modèle à chaque étape de son entraînement est présentée sur les figures ci-dessous.