La tokenisation et le split#
Une fois que nous avons préparé le jeu de données d’affinage de manière appropriée, nous devons procéder à sa tokenisation ! Nous utilisons le même tokenizer que celui du modèle que nous allons affiner.
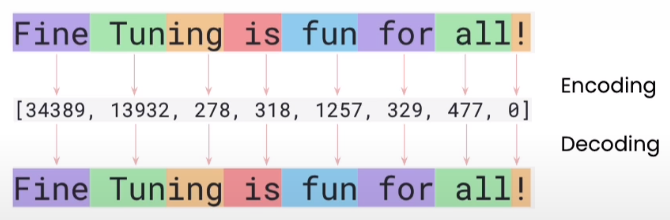
.. attention::
La tokenisation ne signifie pas que chaque mot est traité comme un token. Cela dépend du modèle utilisé.
D’accord, commençons par tokeniser un seul texte a fin d’avoir une idée claire de ce qu’il se passe
import pandas as pd
import datasets
from pprint import pprint
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
text = "ENSAM MEKNES"
encoded_text = tokenizer(text)["input_ids"]
print(encoded_text)
#[18041, 2300, 10616, 25227, 1410]
decoded_text = tokenizer.decode(encoded_text)
Note
La difference entre la tokenisation et la vectorisation la tokenisation consiste à diviser le texte en unités (ou “tokens”) significatives, comme des mots ou des caractères. La vectorisation, quant à elle, consiste à convertir ces tokens en vecteurs numériques afin de les utiliser dans des modèles d’apprentissage automatique. En d’autres termes, la tokenisation prépare les données textuelles en les divisant en parties significatives, tandis que la vectorisation les transforme en une forme utilisable par les algorithmes d’apprentissage automatique.
a fin de tokeniser plusieurs textes à la fois, nous pouvons utiliser le padding, la troncature ou les deux. Cela est nécessaire car les différents textes ont des longueurs différentes et les modèles nécessitent des tailles d’entrée cohérentes.
encoded_texts_both = tokenizer(list_texts, max_length=3, truncation=True, padding=True)
print("Using both padding and truncation: ", encoded_texts_both["input_ids"])
#we can set padding or truncation to False or change the max length as there's an input limit
D’accord, procédons à la tokenisation de l’ensemble du jeu de données au format JSONL.
def tokenize_function(examples):
text = examples["question"][0] + examples["answer"][0]
tokenizer.pad_token = tokenizer.eos_token
tokenized_inputs = tokenizer(
text,
return_tensors="np",
padding=True,
)
max_length = min(
tokenized_inputs["input_ids"].shape[1],
2048
)
tokenizer.truncation_side = "left"
tokenized_inputs = tokenizer(
text,
return_tensors="np",
truncation=True,
max_length=max_length
)
return tokenized_inputs
finetuning_dataset_loaded = datasets.load_dataset("json", data_files=filename, split="train")
tokenized_dataset = finetuning_dataset_loaded.map(
tokenize_function,
batched=True,
batch_size=1,
drop_last_batch=True
)
print(tokenized_dataset)
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, shuffle=True, seed=123)
print(split_dataset)